Quatrième billet d’une série consacrée aux plateformes DMP.
Dans le précédent billet, j’ai exposé mon point de vue – très personnel et donc plein de parti pris – sur la question des avantages et inconvénients respectifs des données 1st Party et données 3rd Party, sans pour autant avoir complètement expliqué ce que sont les données 3rd Party, comment leur utilisation est rendue techniquement possible dans une DMP, ni quels sont ses principaux cas d’usage. Voilà ce que je propose donc de traiter dans ce quatrième billet de la série DMP.
C’est quoi, au juste, les données Third Party ?
La définition courte des données Third Party, c’est des données au niveau individu qui sont achetées – ou plus exactement louées à l’utilisation – auprès d’acteurs dont c’est le métier de collecter puis de monétiser ces données : les 3rd party data vendors. En tant que marketeur utilisant une DMP, ces données ne vous appartiennent pas, vous payez souvent à chaque fois que vous les utilisez (avec un pricing soit au CPM, soit un flat fee « all you can eat ») et parfois certains fournisseurs peuvent imposer des restrictions d’usage. Pour citer quelques noms de fournisseurs de données 3rd Party, on peut mentionner les noms de Acxiom, AddThis, Eyeota, eXelate, ou bien encore VisualDNA.
Le besoin
On l’a expliqué dans le premier article d’introduction, la vraie valeur d’une DMP se trouve dans la capacité à enrichir la connaissance d’un visiteur anonyme, et ceci si possible dès la première page visitée, afin que l’on soit en mesure de présenter les contenus et offres les plus susceptibles d’intéresser cette personne.
Concrètement, sur la première page visitée par un internaute, on ne sait presque rien sur cette personne. On peut récupérer des infos techniques (typiquement : est-ce une visite depuis un desktop ou bien depuis un mobile ? quel est son fournisseur d’accès internet ? quelle est la langue du browser ? est-ce que son adresse IP me permet d’avoir une vague idée de sa géolocalisation ? etc.) mais ça reste très faible…
Avant que cette personne ne se profile en créant un compte dans votre site, aucun espoir de savoir si c’est un homme ou une femme, sa tranche d’âge, s’il y a des enfants dans le foyer, quels sont ses centres d’intérêt, ses intentions d’achat, ses habitudes d’achat, ou bien est-ce que cet individu est « in market » pour le genre de produits que je vends, etc.
C’est là qu’interviennent les données 3rd party : En croisant les données socio-démo / intention / intérêt / etc des fournisseurs de données avec les informations de navigation collectées par la DMP dès la première page visitée, on peut commencer à disposer d’un profil assez riche pour pouvoir personnaliser la home page, mettre en avant des promos ou des produits plus en rapport avec les caractéristiques ainsi obtenues sur ce visiteur qui est pour le moment encore totalement inconnu.
Concrètement
Concrètement, on a d’un côté un fournisseurs de données qui possède un ensemble de critères élémentaires (genre ; âge ; pays ; langue ; etc.) ou bien des traits d’intention (Intentionniste achat auto ou bien Intentionniste Nissan ou bien Intentionniste Nissan GTR) ou bien des segmentations prédéfinies (Jeune urbain technophile et gadgetophile), par exemple – et de l’autre côté nous avons notre DMP qui connaît des visiteurs anonymes à travers un identifiant muet déposé dans un cookie. On l’appellera le DMP_ID.
Chez le fournisseur de données, les données sont collectées et stockées au niveau d’un individu (donc pas d’agrégat). La clé de ces données est donc au niveau d’un individu (*) pour le fournisseur de données. On l’appellera DATAUSER_ID.
(*) = Dans les faits, la majorité des fournisseurs de données gèrent l’unicité au niveau d’un device, et n’agrègent pas les profils d’une même personne sur plusieurs devices. C’est ainsi qu’on peut avoir des fournisseurs de données qui annoncent 80 millions de profils pour le marché Français. Mais pour une question de simplification, considérons tous ces profils comme étant des individus.
L’enjeu donc, pour pouvoir utiliser les données 3rd Party dans la DMP, c’est d’être en mesure de dire que l’individu connu de la DMP comme étant DMP_ID = « abcdef » et la même personne (anonyme) que l’individu connu chez le fournisseur de données comme étant DATAUSER_ID = 123456.
Si on est capable de réaliser ce croisement des profils, alors on pourra superposer les données de la DMP (1st party) et les données 3rd party du fournisseur de données.
Question : comment réaliser ceci ? La réponse, c’est un mécanisme très simple mais très malin (dans les deux sens du terme !) et standard au sein des solutions et plateformes de ad-tech : le « cookie sync » ou bien encore « ID sync ».
Parenthèse : le « Cookie Sync » ou « ID Sync »
Vous n’êtes sans doute pas tous et toutes familiers avec la RFC 2109, datant de Février 1997 et émanant de Netscape, et qui décrit les principes de fonctionnement des cookies dans un web browser.
En ce qui nous concerne, l’aspect qui nous intéresse est qu’un cookie ne peut – par design et pour protéger la privacy et la confidentialité – être lu ou modifié que par le domaine qui l’a créé. Ainsi si je vais sur SiteEcommerce.com et que ce site me dépose un cookie de tracking, plus tard en allant sur SiteMedia.fr, ce dernier ne pourra pas lire le contenu du cookie déposé par SiteEcommerce.com, ni même savoir si un cookie existe ou pas.
Pas moyen de me retargeter, dites-donc, c’est dommage non ?
Mais si. Attendez…
Alors voilà, je n’ai jamais vraiment cherché à savoir qui avait en premier mis au point la « ruse technique » du Cookie Sync, mais c’est assez malin, et totalement conforme aux RFC, même si ça va à l’encontre de leur esprit initial. J’ai tenté de représenter visuellement les séquences d’échanges ayant lieu dans un cookie sync sur le graphique suivant.
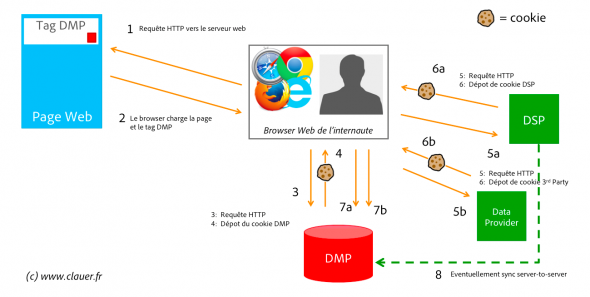
C’est amusant de constater que tout ceci fonctionne en utilisant uniquement les deux ou trois trucs disponibles dans la boite à outils internet : des requêtes HTTP, des cookies, des redirections HTTP, et des pixels 1×1 transparents. Et en gros, c’est tout.
Ainsi, quand un nouvel internaute visite pour la première fois le site Web de la société Acme.com, le tag JavaScript de la DMP présent dans les pages du site Acme.com va créer un nouveau DMP_ID pour ce nouvel individu, et déposer cet ID dans un cookie sur un nom de domaine appartenant à la DMP (soit un cookie third party, du point de vue du nom de domaine acme.com).
Le tag DMP va ensuite faire un appel server-call vers un pixel transparent chez le fournisseur de données 3rd Party, et va ajouter à la fin de l’URL de l’endpoint la mention du DMP_ID, soit au final une URL qui aurait cette forme :
http://dataprovider.com/endpoint/getpixel.htm?DMP_ID=abcdef&PID=42
Le paramètre hypothétique PID serait ici un « Partner ID » informant le fournisseur de données que l’appel provient, dans notre exemple, de la DMP de Adobe.
S’agissant d’une requête HTTP vers le domaine dataprovider.com, s’il existe un cookie de dataprovider.com dans le browser de l’internaute, son contenu est automatiquement envoyé dans les headers HTTP de la requête getpixel.htm. C’est la RFC 2109 qui dit ça. Merci à elle ;)
Ainsi, le fournisseur de données voit arriver une requête sur laquelle il obtient le DMP_ID en paramètre d’URL, et il obtient son propre ID via le cookie dans l’entête HTTP. Le cookie sync est fait du côté du fournisseur de données. Reste maintenant à retourner ça à la DMP.
Or, problème, le endpoint est supposé retourner un pixel transparent 1×1, pas une liste d’IDs. Comment faire ?
Au lieu de répondre à la requête HTTP en renvoyant un contenu, le fournisseur de données va répondre avec un code d’erreur HTTP 302 (=Moved Temporarily) en indiquant une URL… qui est un endpoint vers la DMP Adobe. Et là, de façon symétrique, il suffit à dataprovider.com de rediriger vers une URL telle que :
http://adobedmp.com/sync/endpoint?DATAUSER_ID=123456&PLT=999
Dans lequel le PLT serait une indication pour la DMP Adobe de l’identité de la plateforme appelante, soit 999 = DataProvider.com. Et hop le tour est joué, l’échange et la synchro des IDs a bien eu lieu !
Redoutable, non ? :)
Match tables
Ce principe de ID Sync est le même entre les DMP et les fournisseurs de données, mais aussi avec les DSPs, SSPs, AdExchanges, Adservers, etc.
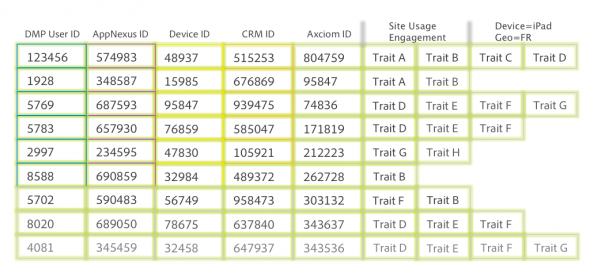
Au final, les DMP gèrent des énormes tables de correspondance pour conserver les valeurs de ID correspondant aux différents profils dans les plateformes externes (DSPs, AdExchanges, 3rd Party data Providers, etc.) Ainsi, quand une DMP envoie un segment d’audience à un DSP tel que AppNexus, elle peut simplement lui envoyer une liste d’ID AppNexus. Le DSP n’a pas besoin de connaitre la correspondance avec l’ID DMP pour pouvoir cibler cet individu. A titre d’illustration, Audience Manager – la DMP de Adobe – gère environ 8,5 milliards de profils actifs au niveau mondial. Ça vous donne une idée de la taille de cette fameuse Match Table.
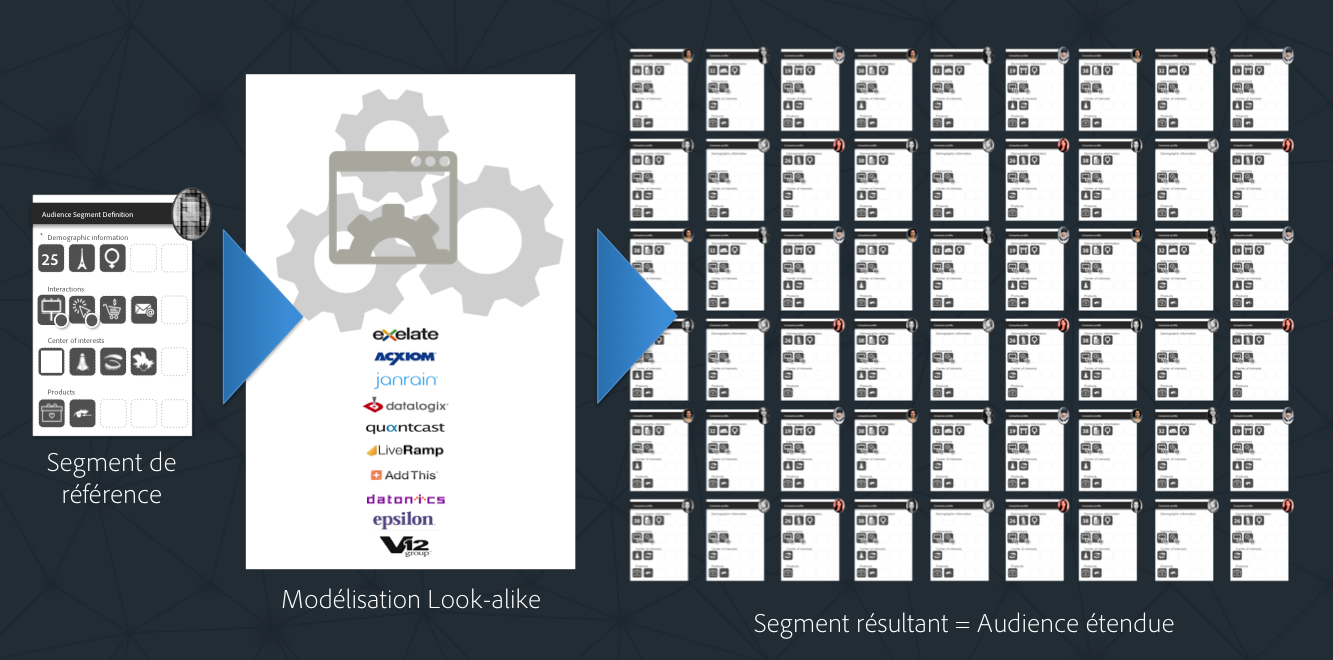
Comment ça fonctionne, le Look-alike Modeling ?
Passons à autre chose, maintenant que j’ai bien fatigué tout le monde à coup de RFP 2109, d’entêtes HTTP et autres trucs incompréhensibles pour la plupart des marketeurs (ceci n’est pas une critique, c’est normal c’est des trucs relativement assez techniques, quoi !).
Parlons maintenant de Look-alike Modeling. Plus question de cookies et de requêtes HTTP. Non. On va parler ici d’algorithmes et de modèles statistiques. C’est tout. Promis.
Principaux cas d’usage
Le cas d’usage indissociable du Look-alike Modeling c’est celui de l’extension d’audience : une fois qu’on a défini dans la DMP un segment correspondant à une audience particulièrement intéressante, par exemple les individus ayant converti, ou ceux présentant un fort potentiel ou une importante CLV (= Customer Lifetime Value), en tant que marketeur on aimerait pouvoir cibler prioritairement ou exclusivement ce genre de profils, et ne pas dépenser du budget média pour adresser des individus en dehors de cette cible, qui sont a priori moins susceptibles de convertir.
Principe de fonctionnement
Le principe de fonctionnement est d’appliquer un algorithme statistique à un ensemble d’individus, notre segment de référence de prospects à fort potentiel par exemple, afin de pouvoir identifier parmi un ensemble de profils inconnus ceux qui présentent des caractéristiques plus ou moins similaires. En général, on recherchera les individus similaires parmi les profils connus d’un fournisseur de données 3rd Party, et on choisira la taille de l’audience résultante que l’on souhaite obtenir en tant que résultat de la modélisation.
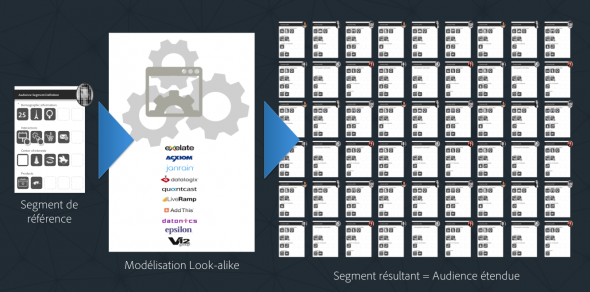
Par exemple, si on est un assureur et qu’on a défini un segment de clients ayant souscrit à des produits d’assurances scolaires, et que ce segment comporte 25,000 individus, on peut soumettre ce segment de référence à une modélisation look-alike, et demander à obtenir en sortie un segment constitué d’une audience de 100,000 ou 500,000 ou 1 million de profils plus ou moins similaires. L’emploi du « plus ou moins similaire » est volontaire, car ceci exprime que plus on souhaitera obtenir un segment large en sortie, plus les individus la constituant seront susceptibles d’avoir des similarités moins fortes avec l’audience de base. C’est un compromis entre le « reach » et la précision par rapport au segment de référence.
Dans le cas de la DMP Adobe – celle que je connais le mieux car c’est celle dont je suis en charge en tant qu’avant-vente – l’algorithme maison nommé TraitWeight est basé sur un algorithme nommé TF-IDF (= Term Frequency / Inverse Document Frequency). Si vous êtes vraiment très curieux, cet algo est décrit ici dans la documentation en ligne de Adobe Audience Manager.
Mais, mais, mais…
Et c’est là que je voulais en venir. Il y a souvent une confusion au niveau de l’intérêt des données 3rd Party entre la qualification des audiences et l’augmentation d’audiences.
Hyper-segmentation = audiences réduites
Plus on ajoute de critères (1st, 2nd ou 3rd Party), et plus on réalise une segmentation fine, alors plus la taille du segment résultant diminue. Un hyper segmentation donnera des segments d’audiences très faibles, qui n’auront que très peu – voire pas du tout – d’impact sur vos objectifs de conversion, acquisition, etc.
Le piège du match-rate
On l’a compris au moment de l’explication du Cookie Sync. Pour pouvoir affiner le profil d’un individu avec des données 3rd Party, il faut que cet individu soit connu à la fois de la DMP et du fournisseur 3rd Party. Concrètement, quand on ajoute un critère de donnée 3rd Party à un segment initialement constitué de données 1st Party (vos visiteurs web), alors de facto on limite la taille de ce segment à l’intersection des individus figurant dans les deux ensembles. Si on a un taux de match de 25% entre notre audience DMP et un fournisseur de données 3rd Party, alors en voulant préciser le profil de notre audience avec des données 3rd Party, on se privera de facto des 3/4 de notre audience. C’est mathématique :)
Et surtout : ne pas confondre Qualification et Extension
In fine, on le comprend bien : si on utilise des données 3rd Party pour qualifier plus finement des profils (ie pour affiner les profils au moyen de données 3rd party supplémentaires), alors on risque de réduire la taille de l’audience résultante. Contrairement à ce qu’on peut lire parfois : Non, la donnée third party n’accroit pas magiquement et d’un seul coup la taille de votre base de données de profils…
En revanche, l’extension d’audience est un mécanisme lié à l’utilisation de modélisations look-alike, en projetant un segment de la DMP vers le cookie pool d’un fournisseur de données 3rd Party, mais dans ce cas, on n’agit pas et on n’améliore pas la connaissance de nos profils dans la DMP.
En conclusion
C’est une confusion qui est assez courante. Il faut avouer que ça n’est pas évident à comprendre de prime abord : il m’a fallu 5 à 6 pages de texte pour l’expliquer relativement clairement. Et il vous aura fallu une bonne dose de patience et de persévérance pour arriver au bout de cet article. Bravo à vous !
A suivre
Le prochain billet portera – peut être – sur les scénarios de données 2nd Party, leur importance et quelques exemples très concrets de case 2nd Party pour les annonceurs. Sauf si d’ici là je choisis de vous parler d’autre chose :)
Disclaimer
Je suis ingénieur avant-vente spécialisé sur la DMP chez Adobe. Néanmoins, je m’attache ici à présenter le sujet DMP de façon neutre, en restant au niveau des généralités, sauf mention contraire. Ce billet fait partie d’une série de billets consacrés aux DMP. Vous pouvez trouver la liste de ces billets via ce lien.



One comment on “DMPSeries #4 – Look-alike modeling et données 3rd Party”
Comments are closed.